自变量与因变量|定义与例子
在研究中,变量是任何可以具有不同值的特征,如身高、年龄、温度或测试分数。
研究人员经常在研究中操纵或测量独立和因变量,以测试因果关系。
你的独立变量是房间的温度。你改变房间的温度,让一半的参与者变冷,另一半的参与者变热。
你的因变量是数学考试成绩。你使用标准化测试来测量所有参与者的数学技能,并检查他们是否因室温而有所不同。
什么是自变量?
一个自变量是你操纵或改变的变量实验研究探索它的影响。它被称为“独立”,因为它不受研究中任何其他变量的影响。
自变量也被称为:
这些术语特别用于统计数据,即估计自变量变化能解释或预测因变量变化的程度。
自变量的类型
自变量主要有两种类型。
- 实验自变量可以被研究人员直接操纵。
- 对象变量不能被研究人员操纵,但它们可以被用来对研究对象进行分类。
实验变量
在实验中,你直接操纵自变量来观察它们是如何影响因变量。自变量通常应用于不同的层次,以了解结果的差异。
为了找出答案,您可以只应用两个级别如果自变量是有影响的。
您还可以应用多个级别来找到答案如何自变量影响因变量。
你有三个自变量水平,每组都有不同的治疗水平。
你随机分配把你的病人分成三组
- 低剂量实验组
- 高剂量实验组
- 安慰剂组(研究一种可能的安慰剂效应)
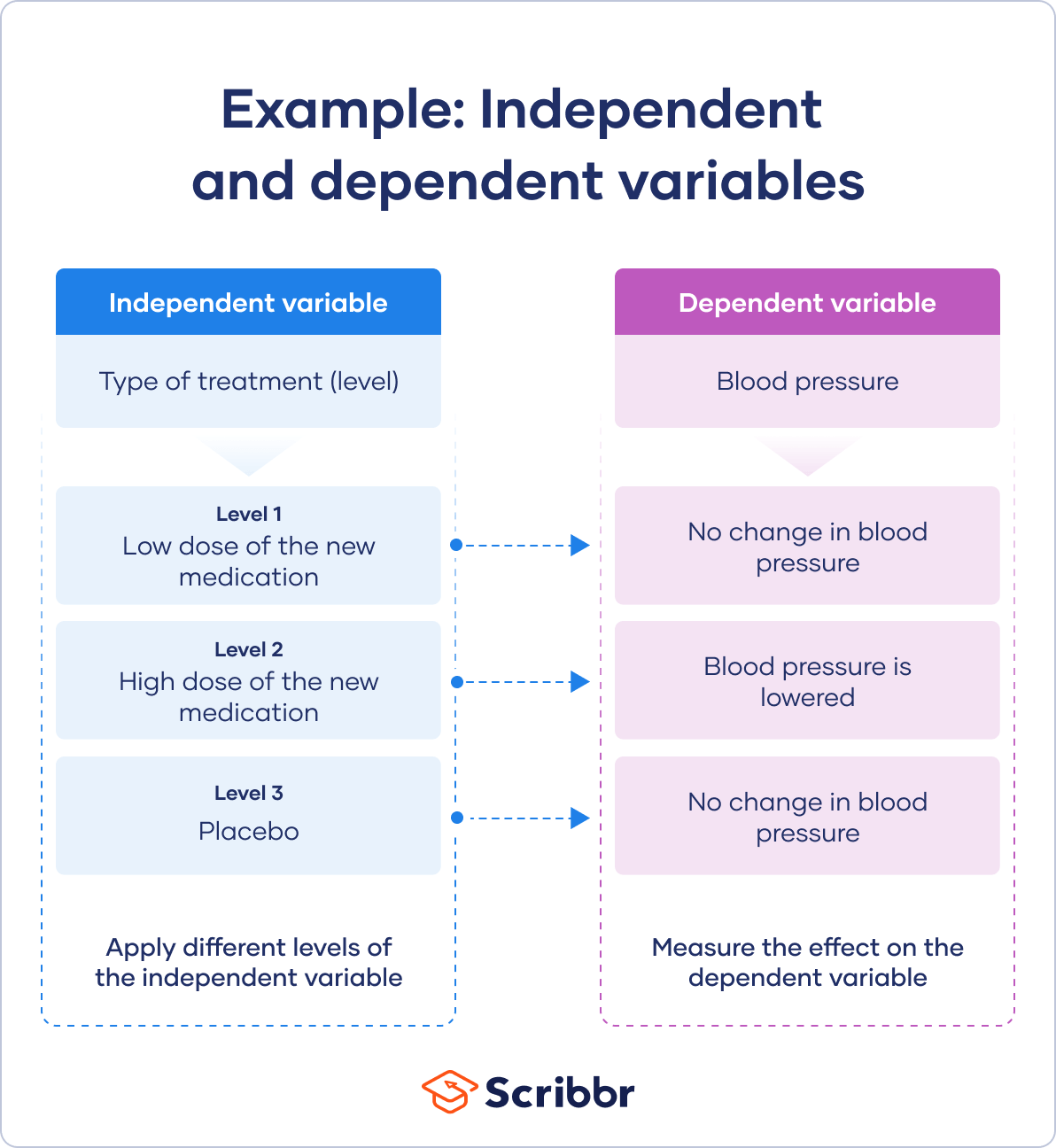
一个真实的实验要求你随机分配不同水平的自变量给你的参与者。
随机分配很有用控制参与者特征,这样他们就不会影响实验结果。这有助于你有信心,你的因变量结果完全来自于自变量的操作。
对象变量
受试者变量是不同参与者的特征,研究人员无法操纵它们。例如,性别认同、民族、种族、收入和教育都是重要的主体变量,社会研究者将其视为自变量。
不可能将这些随机分配给参与者,因为这些是已经存在的群体的特征。相反,你可以创建一个研究设计,在其中比较具有特征的参与者组的结果。这是一个准实验设计因为没有随机分配。请注意,任何使用非随机分配的研究方法都有风险研究偏见就像选择性偏差而且抽样偏差.
你的自变量是一个主体变量,即参与者的性别认同。你分为三组:男性、女性和其他。
你的因变量是听到婴儿哭声时的大脑活动反应。当参与者在无意识的情况下听到婴儿的哭声时,你用功能磁共振成像扫描记录他们的大脑活动。
收集数据后,检查统计上显著两组之间的差异。你找到了一些,并得出结论,性别认同会影响大脑对婴儿哭声的反应。
什么是因变量?
因变量是由于自变量操作而发生变化的变量。这是你感兴趣的测量结果,它“取决于”你的自变量。
在统计数据,因变量也称为:
- 响应变量(他们会对另一个变量的变化做出反应)
- 结果变量(它们代表您想要测量的结果)
- 左边变量(它们出现在回归方程的左边)
因变量是你处理完自变量之后所记录的。您使用这些测量数据进行统计分析,以检查您的自变量是否以及在多大程度上影响因变量。
基于你的发现,你可以估计自变量的变化驱动因变量变化的程度。你也可以预测因变量会因为自变量的变化而改变多少。
识别自变量和因变量
在设计一项复杂的研究或阅读一份学术论文时,区分自变量和因变量可能是一件棘手的事情研究论文.
一项研究中的因变量可能是另一项研究中的自变量,所以注意这一点很重要研究设计.
这里有一些识别每种变量类型的技巧。
识别自变量
使用下面的问题列表来检查你是否在处理一个自变量:
- 该变量是否被研究者操纵、控制或用作受试者分组方法?
- 这个变量在时间上比另一个变量早吗?
- 研究人员是否试图了解这个变量是否或如何影响另一个变量?
识别因变量
检查你是否在处理一个因变量:
- 这个变量是作为研究结果来衡量的吗?
- 这个变量是否依赖于研究中的另一个变量?
- 这个变量是否只有在其他变量改变后才被测量?
研究中的自变量和因变量
这里有一些研究问题的例子和相应的自变量和因变量。
| 研究问题 | 独立变量 | 因变量(s) |
|---|---|---|
| 番茄在荧光灯、白炽灯还是自然光下长得最快? |
|
|
| 间歇性禁食对血糖水平有什么影响? |
|
|
| 医用大麻对慢性疼痛患者是否有效? |
|
|
| 远程工作能在多大程度上提高工作满意度? |
|
|
对于实验数据,通过生成分析结果描述性统计把你的发现形象化。然后,选择一个合适的统计检验来检验你的假设.
测试类型由以下因素决定:
你会经常用到t测试或方差分析分析你的数据并回答你的研究问题。
自变量和因变量的可视化
在定量研究在美国,使用图表将研究结果可视化是一种很好的做法。一般来说,自变量在x-轴(水平)和因变量y设在(垂直)。
你使用的可视化类型取决于你的研究问题中的变量类型:
- 一个条形图当你有一个分类自变量时是理想的。
- 一个散点图或线形图当自变量和因变量都是定量的时候是最好的。
为了检查你的数据,你把治疗水平的自变量放在x-轴和血压的因变量y设在。
每个治疗组在治疗前和治疗后的血压差异。
根据您的结果,您注意到安慰剂组和低剂量组在血压方面的差异很小,而高剂量组则有显著改善。

关于自变量和因变量的常见问题
- 为什么自变量和因变量很重要?
-
确定因果关系是科学研究中最重要的部分之一。重要的是要知道哪个是原因独立变量-哪个是效果-因变量。
- 一个变量可以既独立又相关吗?
-
不。a的值因变量依赖于一个自变量,所以一个变量不能同时是独立的和依赖的。不是原因就是结果,不能两者兼有!
引用这篇Scribbr文章
如果你想引用这个来源,你可以复制和粘贴引用或点击“引用这篇Scribbr文章”按钮,自动添加到我们的免费引用生成器引用。
班达里,P.(202,12月02日)。自变量与因变量|定义与例子。Scribbr。检索于2022年12月30日,来自//www.dandarfirm.com/methodology/independent-and-dependent-variables/
