单向方差分析|何时及如何使用(附示例)
方差分析是方差分析(Analysis of Variance)的缩写统计检验用于分析之间的差异意味着两组以上的。
一个单向方差分析使用一个独立变量,而双向方差分析使用两个自变量。
何时使用单向方差分析
如果有的话,使用单向方差分析收集的数据大约一个分类自变量和一个定量因变量.自变量至少有三个水平(即至少三个不同组别或类别)。
方差分析告诉你因变量是否随着自变量的水平而变化。例如:
- 自变量是社交媒体使用,并将组分配给低,媒介,高社交媒体的使用水平,看看是否有差异每晚的睡眠时间.
- 自变量是汽水品牌,并收集数据可口可乐,百事可乐,雪碧,芬达来找出是否有区别每100毫升价格.
- 自变量是肥料种类你用混合物来处理农田1,2而且3.来找出是否有区别作物产量.
的零假设(H0)的方差分析是组间均值无差异。替代假设(H一个)是至少有一组与因变量的总体平均值显著不同。
如果你只想比较两组,使用at测验代替。
方差分析是如何工作的?
方差分析通过计算处理水平的均值与因变量的总体均值是否不同,来确定由自变量水平创建的组是否具有统计上的差异。
如果组均值中有任何一个显著不同于总体均值,则零假设将被拒绝。
方差分析使用F测试统计显著性.这允许同时比较多个平均值,因为误差是为整个比较集计算的,而不是为每个单独的双向比较计算的t测试)。
的F测试比较方差每一组的均值来自于整个组的方差。如果方差群体内部小于方差团体之间,F考试会找到更高的F值,因此观察到的差异更有可能是真实的,而不是偶然的。
以下是学生们喜欢Scribbr校对服务的原因
方差分析假设
方差分析检验的假设与任何参数检验的一般假设相同:
- 观察的独立性:数据收集采用统计有效抽样方法,并且观察结果之间没有隐藏的关系。如果你的数据不能满足这个假设,因为你有混杂变量你需要在统计上控制,使用一个有阻塞变量的方差分析。
- 正态分布响应变量:因变量的值遵循a正态分布.
- 方差齐性:被比较的每一组内的变化都是相似的。如果各组之间的方差不同,那么方差分析可能就不适合这些数据。
进行单向方差分析
而你可以进行方差分析用手在美国,仅靠几次观察就很难做到这一点。我们将在R统计程序中执行我们的分析,因为它是免费的、强大的并且广泛可用的。有关此ANOVA示例的完整演练,请参阅我们的执行指南R的方差分析.
来自我们假想的作物产量实验的样本数据集包含以下数据:
- 肥料类型(1、2、3型)
- 种植密度(1 =低密度,2 =高密度)
- 田间种植位置(第1、2、3、4座)
- 最终作物产量(蒲式耳/英亩)。
这为我们提供了足够的信息来运行各种不同的方差分析测试,并查看哪个模型最适合数据。
对于单因素方差分析,我们只分析肥料类型对作物产量的影响。
在将数据集加载到R环境后,我们可以使用该命令自动阀()进行方差分析在这个例子中,我们将模拟平均值的差异反应变量作物产量,作为肥料类型的函数。
一个。Way <- aov(yield ~ fertilizer, data = crop.data)
解读结果
要查看R中统计模型的摘要,请使用总结()函数。
总结(one.way)
方差分析测试的总结(在R中)如下所示:
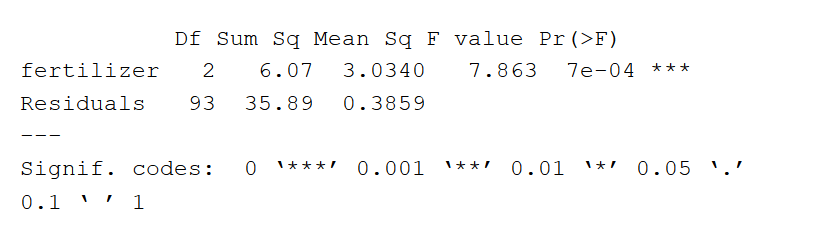
方差分析输出提供了自变量可以解释的因变量中有多少变化的估计。
- 第一列列出独立变量和模型一起残差(也就是模型误差)。
- 的Df列显示自由度对于自变量(用变量内的水平数减去1计算)和残差的自由度(用观察总数减去1,然后减去每个自变量的水平数计算)。
- 的平方之和列显示了组均值和由该变量解释的总体均值之间的平方和(也就是总变异)。肥料变量的平方和为6.07,残差的平方和为35.89。
- 的意思是平方列是平方和的平均值,由平方和除以自由度来计算。
- 的F价值列是检验统计量从F检验:每个自变量的均方除以残差的均方。越大F值越大,与自变量相关的变化就越有可能是真实的,而不是偶然的。
- 的公关(F >)列是p价值的F统计。这表明,它是多么有可能F从测试中计算的值将会发生零假设组间均值无差异。
因为p自变量肥料的值为统计上显著(p< 0.05),可能肥料类型对作物平均产量有显著影响。
事后测试
方差分析会告诉你自变量的水平之间是否存在差异,但不会告诉你哪些差异是显著的。为了发现治疗水平之间的差异,执行TukeyHSD (Tukey 's honest - significant Difference)事后测试。
TukeyHSD (one.way)
Tukey测试在每个组之间进行两两比较,并使用保守的误差估计来找到统计上彼此不同的组。
TukeyHSD的输出如下所示:
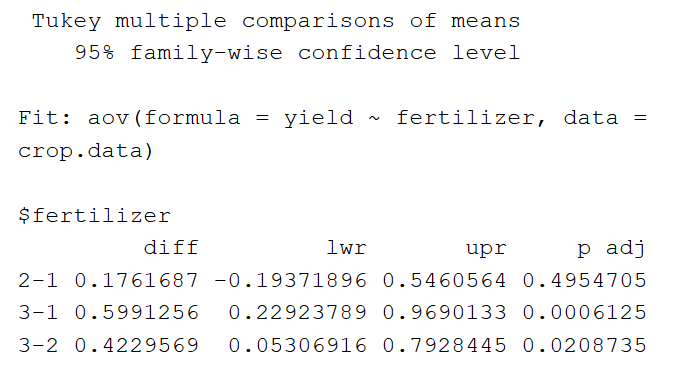
首先,该表报告正在测试的模型(“Fit”)。接下来,它列出了自变量组之间的两两差异。
在“$fertilizer”部分,我们可以看到每种肥料处理之间的平均差异(“diff”),即95%的下限和上限置信区间(' lwr '和' upr '),以及p价值,针对多个成对比较进行了调整。
两两比较表明,肥料3的平均产量显著高于肥料2和肥料1,但肥料2和肥料1的平均产量差异不具有统计学意义。
报告方差分析结果
当报告方差分析的结果时,包括对测试变量的简要描述F价值,自由度,以及p每个自变量的值,并解释结果的含义。
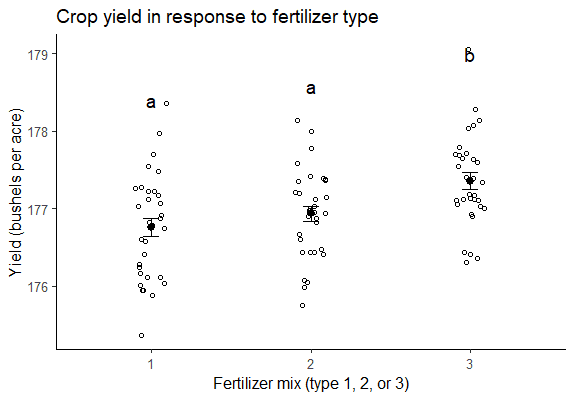
如果您想提供关于在测试中发现的差异的更详细的信息,您还可以包含方差分析结果图,在自变量的每个级别上用分组字母表示,以显示哪些组在统计上彼此不同:
关于单向方差分析的常见问题
引用这篇Scribbr文章
如果你想引用这个来源,你可以复制和粘贴引用或点击“引用这篇Scribbr文章”按钮,自动添加到我们的免费引用生成器引用。
贝文斯,R.(2022年11月17日)。单向方差分析|何时以及如何使用它(附示例)。Scribbr。检索于2022年12月13日,来自//www.dandarfirm.com/statistics/one-way-anova/
