混淆变量|定义,示例和控制
在调查潜在因果关系的研究中,一种混杂变量是未测量的第三个变量这既影响了假设的原因也影响了假设的结果。
重要的是要考虑潜在的混淆变量,并在你的研究设计以确保你的结果是有效的.如果不加检查,混淆变量可能会引入许多变量研究偏见对你的工作造成影响,导致你对结果产生误解。
什么是混杂变量?
混淆变量(又称混淆因素或混淆因素)是一种随机变量这与一项研究有关自变量和因变量.一个变量必须满足两个条件才能成为混淆符:
- 一定是这样相关用自变量。这可能是一种因果关系,但并不一定是。
- 它一定和因变量有因果关系。
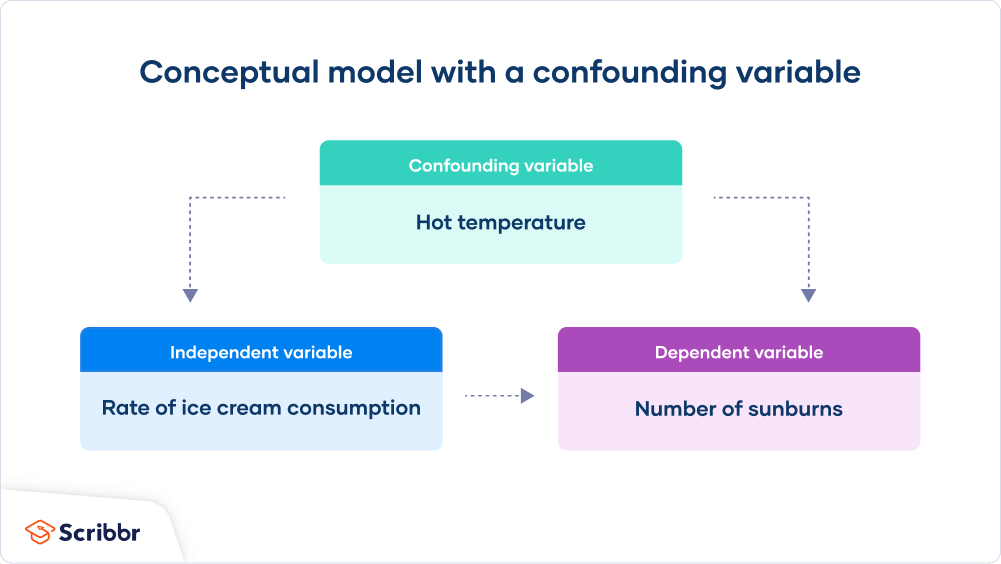
这里的混杂变量是温度:高温会导致人们吃更多的冰淇淋,并在户外晒太阳,从而导致更多的晒伤。
为什么混杂变量很重要
以确保内部效度在你的研究中,你必须考虑到混杂变量。如果你没有这样做,你的结果可能不能反映你感兴趣的变量之间的实际关系,使你的结果有偏差。
例如,你可能会发现一个实际上并不存在的因果关系,因为你测量的结果是由混淆变量引起的(而不是由你的自变量引起的)。这可能会导致忽略变量偏差或安慰剂效应,以及其他偏见。
不一定。也许就业市场较好的州更有可能提高最低工资,而不是相反。在分析最低工资对就业的影响时,你必须考虑之前的就业趋势,否则你可能会发现一个不存在的因果关系。
即使正确地确定了因果关系,混淆变量也会导致高估或低估自变量对因变量的影响。
以下是学生们喜欢Scribbr校对服务的原因
如何减少混杂变量的影响
有几种方法可以解释混淆变量。你可以在学习任何类型的主题时使用以下方法——人类、动物、植物、化学物质等。每种方法都有其优点和缺点。
限制
在这种方法中,通过只包括具有相同潜在混杂因素值的受试者来限制治疗组。
由于这些值在您的研究对象之间没有差异,因此它们不能与您的自变量相关联,因此不能混淆您正在研究的因果关系。
- 相对容易实现
- 极大地限制了你的样本
- 你可能没有考虑到其他潜在的混杂因素
匹配
在此方法中,选择与治疗组相匹配的对照组。对照组的每个成员都应在治疗组中有一个对应的潜在混杂因素值相同,但自变量值不同。
这可以消除混杂变量的差异导致治疗组和对照组之间结果差异的可能性。如果你已经考虑了任何潜在的混杂因素,那么你就可以得出这样的结论:自变量的差异一定是因变量变化的原因。
每一个低碳水化合物饮食的受试者都与另一个没有饮食的具有相同特征的受试者相匹配。因此,对于每一个遵循低碳水化合物饮食的40岁受过高等教育的男性,你会找到另一个没有遵循低碳水化合物饮食的40岁受过高等教育的男性,来比较两者之间的减肥效果。你对你的治疗样本中的所有其他受试者做同样的事情。
- 允许您包含更多的主题而不是限制
- 因为你需要在每个潜在的混杂变量上匹配成对的受试者,所以很难实现吗
- 其他无法匹配的变量也可能是混淆变量
统计性的控制
如果您已经收集了数据,您可以将可能的混杂因素包括为控制变量在你的回归模型;这样,就可以控制混杂变量的影响。
潜在的混杂变量对因变量的任何影响都将在回归结果中显示出来,并允许您分离自变量的影响。
- 易于实施
- 可在数据收集
- 您只能控制直接观察到的变量,但其他未解释的混淆变量可能仍然存在
随机化
另一种最小化混杂变量影响的方法是随机化自变量的值。例如,如果你的一些参与者被分配到一个治疗组,而其他人在一个治疗组对照组,你可以随机分配每组参与者。
随机化确保在足够大的样本中,所有潜在的混杂变量(即使是那些你在研究中不能直接观察到的变量)在不同组之间具有相同的平均值。由于这些变量在分组分配中没有差异,它们不能与你的自变量相关,因此不能混淆你的研究。
由于这种方法允许您解释所有潜在的混杂变量,这几乎是不可能的,它通常被认为是减少混杂变量影响的最佳方法。
随机化保证了治疗组(低碳水化合物饮食组)和对照组不仅具有相同的平均年龄、教育程度和运动水平,而且在其他未测量的特征上也具有相同的平均值。
- 允许您解释所有可能的混淆变量,包括那些您可能无法直接观察到的变量
- 被认为是最小化混杂变量影响的最佳方法
- 最难执行
- 必须在开始数据收集之前实现
- 您必须确保只有治疗组(而不是对照组)的人接受治疗
关于混淆变量的常见问题
引用这篇Scribbr文章
如果你想引用这个来源,你可以复制和粘贴引用或点击“引用这篇Scribbr文章”按钮,自动添加到我们的免费引用生成器引用。
托马斯,L.(2022, 11月25日)。混淆变量|定义,示例和控制。Scribbr。检索于2022年12月30日,来自//www.dandarfirm.com/methodology/confounding-variables/
