双向方差分析|例子&何时使用它
方差分析是一个统计检验用于分析两组以上均值之间的差异。
一个双向方差分析用于估计如何的意思是的定量变量根据两个分类变量的水平变化。当你想知道两个自变量组合如何影响一个因变量时,使用双向方差分析。
你可以使用一个双向方差分析来找出肥料类型和种植密度是否有影响效果平均作物产量。
何时使用双向方差分析
你可以使用双向方差分析收集的数据在定量上因变量在两个分类自变量的多个层次上。
一个定量变量表示事物的数量或计数。它可以被除法得到一组均值。
一个分类变量表示事物的类型或类别。级别是类别变量中的单个类别。
在你的数据集中,你应该有足够的观察数据,以便能够找到每个自变量水平组合的定量因变量的平均值。
两个自变量都应该是分类的。如果一个自变量是分类变量,另一个是定量变量,则使用ANCOVA。
方差分析是如何工作的?
方差分析检验显著性使用F测试统计显著性.的F测试是分组比较测试,这意味着它比较方差每一组的均值为因变量的总方差。
如果组内方差小于组间方差,则为F考试会找到更高的F值,因此观察到的差异更有可能是真实的,而不是偶然的。
双向方差分析与交互测试三零假设同时:
- 在第一个自变量的任何水平上,组均值没有差异。
- 在第二个自变量的任何水平上,组均值没有差异。
- 一个自变量的作用不依赖于另一个自变量的作用(也就是没有相互作用)。
没有相互作用的双向方差分析(又称加性双向方差分析)只检验了前两个假设。
| 零假设(H)0) | 备选假设(H)一个) |
|---|---|
| 平均产量没有差异 适用于任何肥料类型。 |
不同肥料类型的平均产量有所不同。 |
| 两种种植密度的平均产量无差异。 | 种植密度不同,平均产量也有差异。 |
| 一个自变量对平均产量的影响不依赖于另一个自变量的影响(即没有相互作用)。 | 种植密度和施肥类型对平均产量有交互作用。 |
以下是学生们喜欢Scribbr校对服务的原因
双向方差分析的假设
要使用双向方差分析,你的数据应该满足某些假设。双向方差分析makes all of the normal assumptions of a parametric test of difference:
- 方差同质性(也称方差同质性)。方差齐性)
被比较的每一组的平均值周围的变化在所有组中应该是相似的。如果您的数据不符合这个假设,您可以使用非参数的选择比如Kruskal-Wallis测试。
- 观察的独立性
你的自变量不应该相互依赖(即一个不应该导致另一个)。这是不可能用分类变量来测试的——它只能通过良好的状态来确保实验设计.
此外,你的因变量应该代表唯一的观察结果——也就是说,你的观察结果不应该以地点或个体为单位分组。
如果你的数据不符合这个假设(即如果你设置了实验在块内处理),您可以包括一个块变量和/或使用重复测量方差分析。
- 正态分布因变量
因变量的值应该遵循钟形曲线(它们应该是)正态分布).如果您的数据不符合这个假设,您可以尝试数据转换。
如何进行双向方差分析
来自我们假想的作物产量实验的数据集包括以下观察结果:
- 最终作物产量(蒲式耳/英亩)
- 使用的肥料类型(肥料类型1、2或3)
- 种植密度(1=低密度,2=高密度)
- 在字段(1,2,3,4)中阻塞。
双向方差分析将检验自变量(肥料类型和种植密度)是否对因变量(作物平均产量)有影响。但是数据中还有一些其他可能的变化来源,我们需要考虑。
我们将实验处理应用于区块,所以我们想知道种植区块是否会对平均作物产量产生影响。我们还想检查两个自变量之间是否存在相互作用——例如,种植密度可能会影响植物吸收肥料的能力。
因为我们的变量之间有一些不同的可能关系,我们将比较三个模型:
- 没有任何交互作用或阻塞变量的双向方差分析(又称加性双向方差分析)。
- 有交互作用但无阻塞变量的双向方差分析。
- 具有交互作用和阻塞变量的双向方差分析。
模型1假设两个自变量之间没有相互作用。模型2假设两个自变量之间存在相互作用。模型3假设变量之间存在交互作用,并且阻塞变量是数据变化的重要来源。
通过对我们的数据运行所有三个版本的双向方差分析,然后比较模型,我们可以有效地测试哪些变量以及哪些组合对于描述数据是重要的,并查看种植块是否对平均作物产量有影响。
这不是进行分析的唯一方法,但它是一种基于您认为合理的变量组合来高效比较模型的好方法。
在R中进行双向方差分析
我们将在r中运行分析。要自己尝试,请下载样例数据集。
将数据加载到R环境后,我们将使用自动阀()命令,然后使用aictab ()命令。有关完整的演练,请参阅R的方差分析.
第一个模型没有预测自变量之间的任何相互作用,所以我们用“+”把它们放在一起。
两个。Way <- aov(产量~肥料+密度,data = crop.data)
在第二个模型中,为了测试肥料类型和种植密度的相互作用是否影响最终产量,用“*”表示你也想知道相互作用的效果。
交互作用<- aov(产量~肥料*密度,data = crop.data)
因为我们的作物处理是在块内随机的,所以我们在第三个模型中添加了这个变量作为块因子。然后,我们可以比较有和没有阻塞变量的双向方差分析,看看种植位置是否重要。
块<- aov(产量~肥料*密度+块,data = crop.data)
模型比较
现在我们可以使用AIC()找出最适合我们数据的模型。赤池信息标准)模型选择。
AIC通过寻找在使用最少参数的情况下解释响应变量中最大变化量的模型来计算最佳拟合模型。我们可以在R中使用aictab ()函数。
库(AICcmodavg)模型。Set <- list(2。方式,交互,阻塞)model.names <- c("二。方式”,“交互”,“阻塞”)aictab(模型。设置,modnames = model.names)输出如下所示:
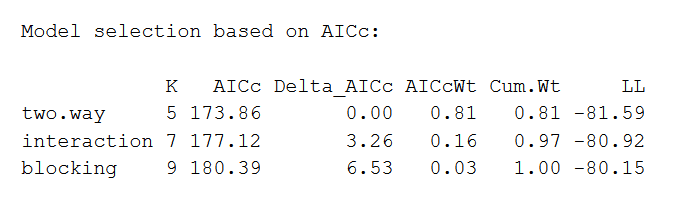
最适合的AIC模型将首先列出,其次列出,依此类推。这一比较表明,没有交互作用或阻塞效应的双向方差分析是最适合数据的。
解释双向方差分析的结果
方法可以查看R中双向模型的摘要总结()命令。我们将看一看第一个模型的结果,我们发现它最适合我们的数据。
总结(two.way)
输出如下所示:
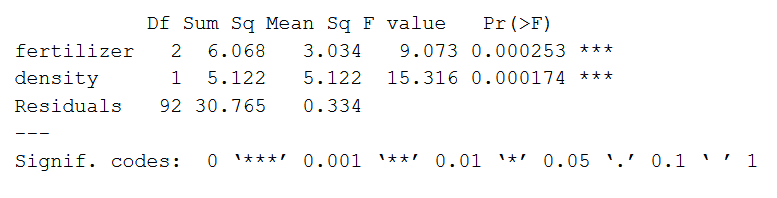
模型摘要首先列出了被测试的自变量(“肥料”和“密度”)。接下来是剩余方差(“残差”),这是因变量中不能被自变量解释的变化。
下面的列提供了解释模型所需的所有信息:
- Df显示了自由度对于每个变量(变量中的层数减去1)。
- 平方之和是平方和(也就是由自变量的水平和总体平均值创建的组均值之间的变化)。
- 意思是平方显示平方和的平均值(平方和除以自由度)。
- F值是检验统计量从F检验(变量的均方除以每个参数的均方)。
- 公关(F >)是p价值的F统计,并显示有多大的可能性是F从F如果零假设为真,检验就会发生。
从这个产量我们可以看到,肥料类型和种植密度都解释了平均作物产量的显著差异(p值< 0.001)。
事后测试
方差分析会告诉你参数是重要的,但不是哪些级别实际上彼此不同。为了测试这一点,我们可以使用事后测试。Tukey 's honest - significant - difference (TukeyHSD)测试让我们看到哪些组彼此不同。
TukeyHSD (two.way)
输出如下所示:

该输出显示了三种类型的肥料($fertilizer)和两种种植密度水平($density)之间的两两差异,以及平均差异(' diff '),即95%的下限和上限置信区间(' lwr '和' upr ')和p差值(' p-adj ')。
从事后测试结果中,我们看到有显著差异(p< 0.05)介于:
- 肥料组3和1,
- 肥料类型3和2,
- 两级种植密度,
但肥料组2和1之间没有差异。
如何呈现一个双向方差分析的结果
在报告结果时,您应该包括F统计量,自由度,以及p值从您的模型输出。
Tukey事后试验显示,肥料组合3和肥料组合1(在组合3下+ 0.59蒲式耳/英亩)、肥料组合3和肥料组合2(在组合2下+ 0.42蒲式耳/英亩)以及种植密度2和种植密度1(在密度2下+ 0.46蒲式耳/英亩)之间存在显著的两两差异。
你可以讨论这些发现的意义讨论部分你的论文。
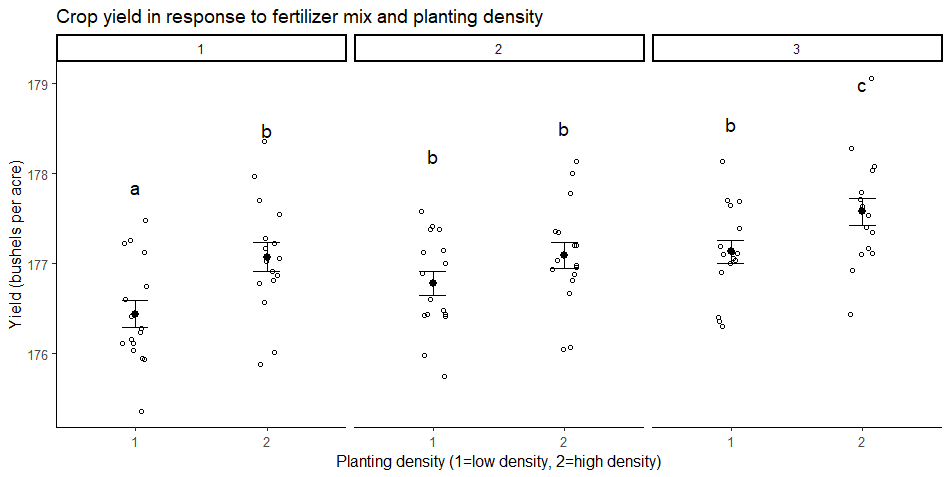
你可能也想知道制作图表来说明你的发现。
你的图表应该包括在方差分析中测试的分组比较,原始数据点,汇总统计数据(在这里表示为均值和标准错误柱状图),以及组上方的字母或显著性值,以显示哪些组与其他组显著不同。
关于双向方差分析的常见问题
引用这篇Scribbr文章
如果你想引用这个来源,你可以复制和粘贴引用或点击“引用这篇Scribbr文章”按钮,自动添加到我们的免费引用生成器引用。
贝文斯,R.(2022年11月17日)。双向方差分析|例子&何时使用它。Scribbr。检索于2022年12月15日,来自//www.dandarfirm.com/statistics/two-way-anova/
