如何找到异常值| 4个方法与例子和解释
离群值是与数据集中大多数其他数据点不同的极值。他们会对你有很大的影响统计分析并歪曲任何的结果假设测试.
仔细识别数据集中的潜在异常值并以适当的方式处理它们以获得准确的结果是很重要的。
什么是异常值?
离群值是位于数据集两端的值。
一些异常值代表种群中自然变异的真实值。其他异常值可能由不正确的数据输入、设备故障或其他原因引起测量误差.
异常值并不总是一种脏数据或不正确的数据,所以你必须小心对待它们数据清理.您应该如何处理异常值取决于其最可能的原因。
真正的离群值
真实的异常值应该始终保留在您的数据集中,因为它们只代表您的数据集中的自然变化样本.
正如预期的那样,大多数值都以中间为中心。但这些极端值也代表了自然变化,因为像运行时间这样的变量受到许多其他因素的影响。
真正的离群值也存在于具有倾斜分布的变量中,其中许多数据点分布远离的意思是在一个方向。选择很重要适当的统计检验或者当你有一个倾斜分布或许多异常值。
其他异常值
不代表真实值的异常值可能来自许多可能的来源:
- 测量误差
- 数据输入或处理错误
- 代表性抽样
对于其中一个参与者,您在他们的冲刺过程中不小心启动了计时器。你将这个计时记录为它们的运行时间。
这个数据点在你的数据集中是一个很大的异常值,因为它要低得多比所有其他的时间。
这种类型的异常值是有问题的,因为它是不准确的,可以扭曲您的研究成果.
在实践中,很难区分不同类型的异常值。虽然您可以使用计算和统计方法来检测异常值,但将它们分类为真或假通常是一个主观的过程。
计算异常值的四种方法
根据您的时间和资源,可以从几种方法中进行选择来检测异常值。
排序方法
你可以排序定量变量从低到高,扫描极低或极高的值。标记您找到的任何极值。
这是在使用更复杂的方法之前检查是否需要调查某些数据点的简单方法。
| 180 | 156 | 9 | 176 | 163 | 1827 | 166 | 171 |
将值从低到高排序,并扫描极端值。
| 9 | 156 | 163 | 166 | 171 | 176 | 180 | 1872 |
使用可视化
你可以使用软件可视化你的数据用一个箱形图,或者一个盒须图,这样你就可以一目了然地看到数据分布。这种类型的图表突出显示最小值和最大值范围),中位数,以及数据的四分位范围。
许多计算机程序用星号突出图表上的异常值,而这些异常值将位于图表的边界之外。
统计异常值检测
统计异常值检测涉及应用统计测试或者确定极值的程序。
您可以将极端数据点转换为z分数这表示离均值有多少个标准差远。
如果一个值的值足够高或足够低z分数,它可以被认为是一个异常值。根据经验,z值大于3或小于-3的值通常被确定为离群值。
使用四分位范围
的四分位范围(IQR)告诉你数据集中间一半的范围。您可以使用IQR在数据周围创建“围栏”,然后将异常值定义为落在这些围栏之外的任何值。
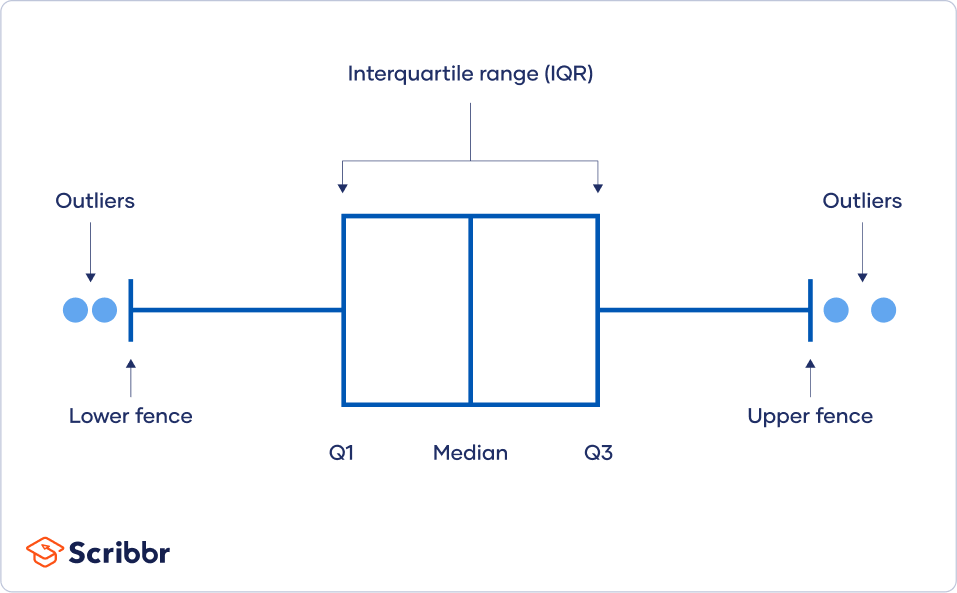
如果您在数据集的极端端有一些值,但不确定其中是否有可能算作异常值,则此方法非常有用。
四分位间距法
- 将数据从低到高排序
- 确定第一个四分位数(Q1),中位数和第三四分位数(Q3)。
- 计算你的IQR = Q3 - Q1
- 计算你的上栅栏= Q3 + (1.5 * IQR)
- 计算你的下栅栏= Q1 - (1.5 * IQR)
- 使用围栏突出显示任何异常值,所有落在围栏之外的值。
你的离群值是任何大于你的上栅栏或小于你的下栅栏的值。
示例:使用四分位范围找到异常值
我们将通过一个逐步的示例引导您了解用于识别异常值的流行IQR方法。
你的数据集有11个值。您的数据集中有几个极端值,因此您将使用IQR方法来检查它们是否是异常值。
| 25 | 37 | 24 | 28 | 35 | 22 | 31 | 53 | 41 | 64 | 29 |
步骤1:将数据从低到高排序
首先,您只需按升序对数据进行排序。
| 22 | 24 | 25 | 28 | 29 | 31 | 35 | 37 | 41 | 53 | 64 |
步骤2:确定中位数,第一个四分位数(Q1)和第三个四分位数(Q3)
的中位数当所有值从低到高排序时,恰好位于数据集中间的值。
因为你有11个值,中位数是第6个值。中位数是31。
| 22 | 24 | 25 | 28 | 29 | 31 | 35 | 37 | 41 | 53 | 64 |
接下来,我们将使用排除法用于识别Q1和Q3。这意味着我们从计算中删除了中位数。
Q1是数据集前半部分的中间值,不包括中位数。第一个四分位数是25。
| 22 | 24 | 25 | 28 | 29 |
您的Q3值位于数据集的后半部分的中间,不包括中位数。第三个四分位数是41。
| 35 | 37 | 41 | 53 | 64 |
第三步:计算IQR
IQR是数据集中间一半的范围。用Q3减去Q1计算IQR。
| 公式 | 计算 |
| Iqr = q3 - q1 | Q1 = 26 Q3 = 41 Iqr = 41 - 26 = 15 |
第四步:计算上面的栅栏
上面的栅栏是围绕第三个四分之一的边界。它告诉您任何超过上栅栏的值都是异常值。
| 公式 | 计算 |
| 上栅栏= Q3 + (1.5 * IQR) | 上栅栏= 41 + (1.5 * 15) = 41 + 22.5 = 63.5 |
第五步:计算你的低栅栏
下面的栅栏是围绕第一个四分位数的边界。任何小于下栅栏的值都是异常值。
| 公式 | 计算 |
| 下栅栏= Q1 - (1.5 * IQR) | 下栅栏= 26 - (1.5 * IQR) = 26 - 22.5 = 3.5 |
第六步:用围栏突出任何异常值
回到步骤1中排序的数据集,并突出显示大于上栅栏或小于下栅栏的任何值。这些是你的异常值。
- 上栅栏= 63.5
- 下栅栏= 3.5
| 22 | 24 | 25 | 28 | 29 | 31 | 35 | 37 | 41 | 53 | 64 |
在数据集中发现一个异常值64。
处理异常值
一旦确定了异常值,就可以决定如何处理它们。您的主要选择是从数据集中保留或删除它们。这和你面临的选择类似处理缺失数据.
对于每个离群值,在决定之前要考虑它是一个真值还是一个错误。
- 离群值是否与来自同一参与者的其他测量值一致?
- 这个数据点是完全不可能的还是可以合理地来自你的人口?
- 异常值最有可能的来源是什么?这是自然变异还是错误?
一般来说,您应该尽可能多地接受异常值,除非很明显它们代表错误或坏数据。
保留离群值
就像丢失值一样,最保守的选择是在数据集中保留异常值。当您不确定它们是否是错误时,保留异常值通常是更好的选择。
对于大样本,异常值是预期的,更有可能出现。但是每个离群值的效果当你的样本足够大的时候。的集中趋势而且可变性当你有大量的值时,你的数据不会受到几个极端值的影响。
如果你有一个小数据集,你可能还想保留尽可能多的数据,以确保你有足够的数据统计能力.如果您的数据集最终包含许多异常值,您可能需要使用对它们更健壮的统计测试。非参数统计检验对这些数据表现更好。
删除离群值
异常值删除意味着在执行之前从数据集中删除极端值统计分析.您的目标是删除任何脏数据,同时保留真正的极端值。
这是一个棘手的过程,因为通常不可能确切地区分这两种类型。删除真正的异常值可能会导致有偏见的数据集和不准确的结论。
因此,只有在有正当理由的情况下才应该删除异常值。重要的是要记录下你删除的每个异常值和你的原因,以便其他研究人员可以遵循你的程序。
关于异常值的常见问题
引用这篇Scribbr文章
如果你想引用这个来源,你可以复制和粘贴引用或点击“引用这篇Scribbr文章”按钮,自动添加到我们的免费引用生成器引用。
班达里,P.(2022年11月11日)。如何找到异常值| 4个方法与例子和解释。Scribbr。2023年1月6日,从//www.dandarfirm.com/statistics/outliers/检索
