计算范围,IQR,方差,标准偏差
可变性描述数据点彼此之间以及与分布中心之间的距离。同时还有集中趋势,可变性的测量给你描述性统计总结你的数据。
变异性也被称为扩散、分散或分散。最常用的测量方法是:
为什么可变性很重要?
而集中趋势,或平均,告诉你你的大部分点在哪里,可变性总结了它们之间的差距。这一点很重要,因为可变性的大小决定了你能做到多好概括从样本到总体的结果。
低可变性是理想的,因为这意味着您可以更好地预测信息人口基于样本数据。高可变性意味着数值不太一致,因此更难进行预测。
数据集可以具有相同的集中趋势,但不同水平的可变性或反之亦然.如果你只知道集中趋势或变异性,你就不能说其他方面。它们一起为您提供数据的完整图像。
使用简单随机抽样,你从3组中收集数据:
- 样本A:高中生,
- 样本B:大学生,
- 样本C:成年全职员工。
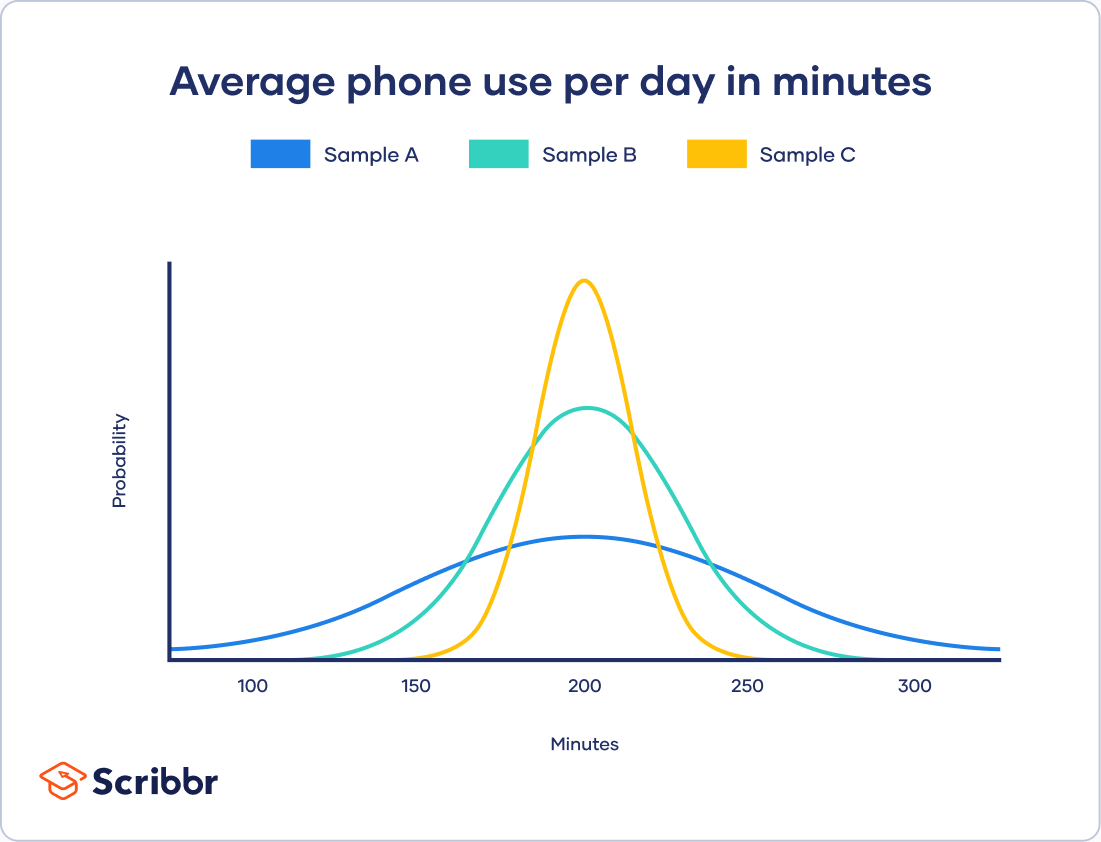
你的三个样本都有相同的平均手机使用时间,都是195分钟或3小时15分钟。这是曲线峰值所在的x轴值。
虽然数据遵循一个正态分布,每个样品有不同的扩散。样本A变异性最大,而样本C变异性最小。
范围
的范围告诉您数据在分布中从最低值到最高值的分布。这是衡量可变性最容易计算的方法。
来找到范围,只需用数据集中的最高值减去最低值。
| 数据(分钟) | 72 | 110 | 134 | 190 | 238 | 287 | 305 | 324 |
|---|
最高值(H)是324最低的(l)是72.
R=H- - - - - -l
R= 324 - 72 =252
数据的范围是252分钟.
由于只使用了2个数字,因此范围受到离群值没有给出任何关于值分布的信息。它最好与其他措施结合使用。
四分位范围
的四分位范围给出了分布的中间分布。
对于任何从低到高排序的分布,四分位数范围包含一半的值。而第一个四分位数(Q1)包含前25%的值,第四个四分位数(Q4)包含后25%的值。
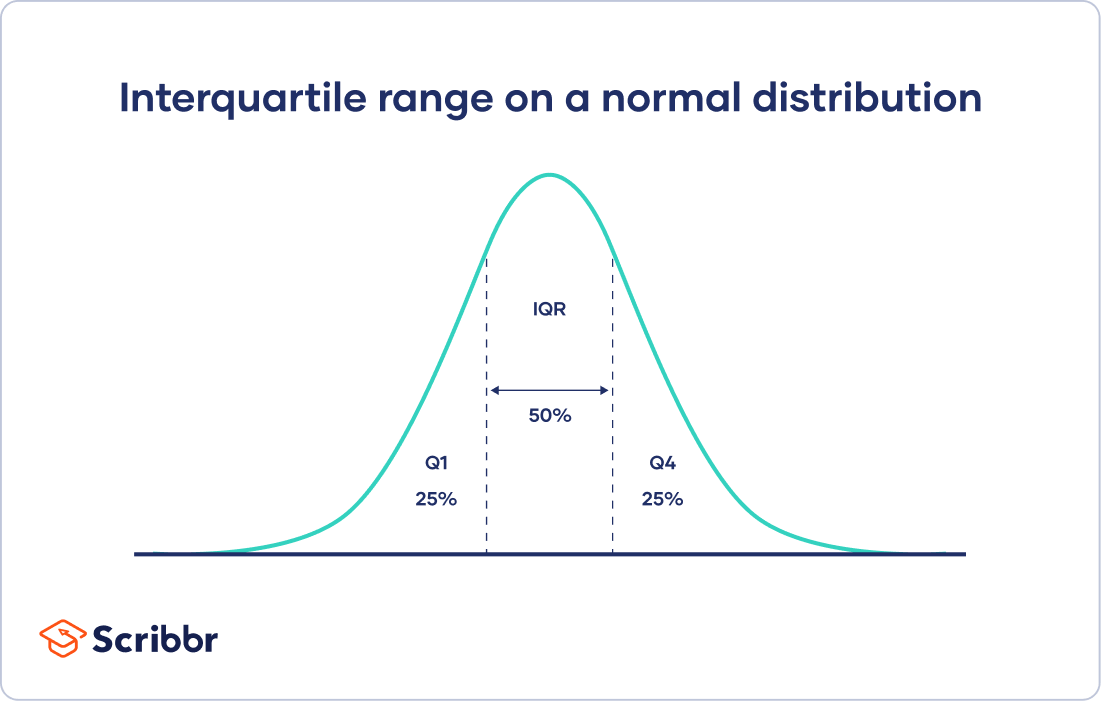
四分位数范围是第三四分位数(Q3)减去第一四分位数(Q1)。这给了我们一个数据集中间一半的范围。
将数据集(8)中的值的数量乘以0.25(第25百分位(Q1)),乘以0.75(第75百分位(Q3)。
Q1位置:0.25 x 8 = 2
Q3位置:0.75 x 8 = 6
Q1是第二个位置的值,也就是110.Q3是第6位的值,也就是287.
Iqr = q3 - q1
Iqr = 287 - 110 =177
数据的四分位范围为177分钟.
与范围一样,四分位范围在计算中只使用2个值。但是IQR受到的影响较小离群值:这2个值来自数据集的中间部分,因此它们不太可能是极端分数。
IQR给出了一个一致的测量变量倾斜还有正态分布。
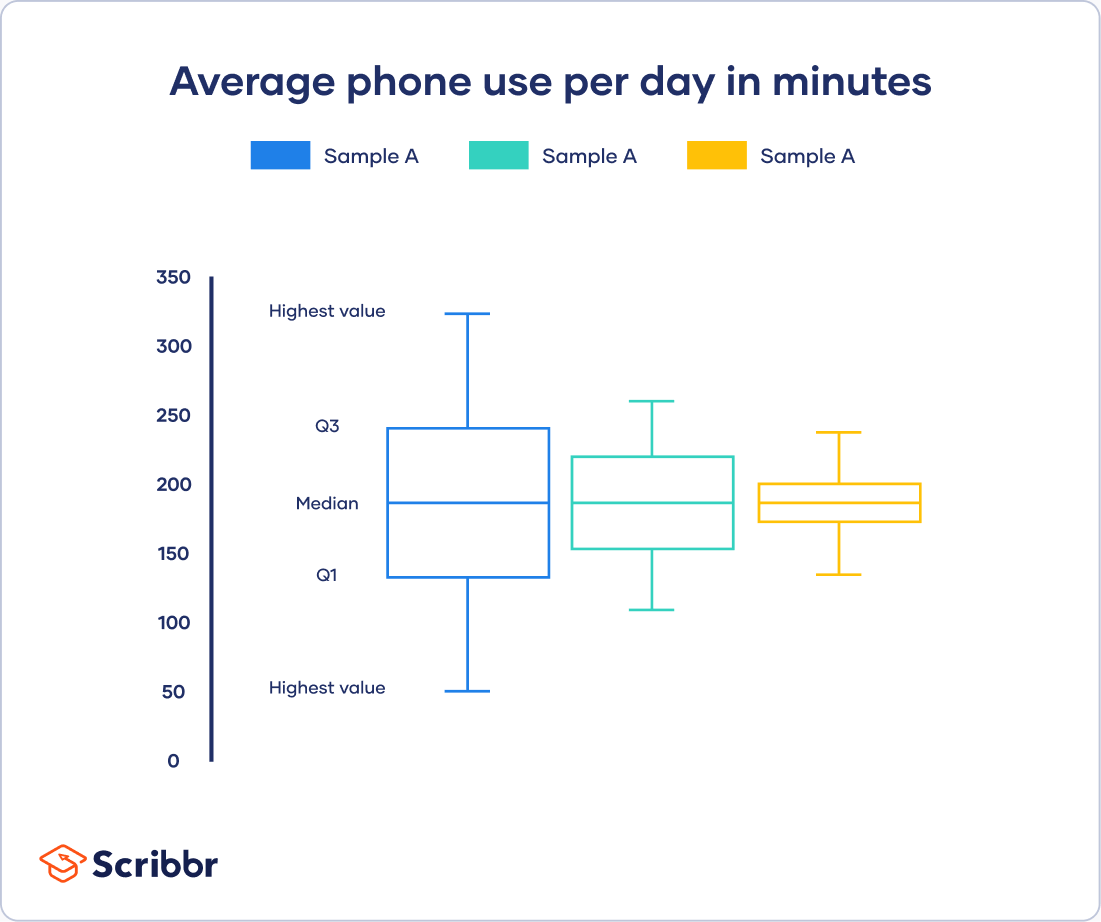
Five-number总结
每个发行版都可以使用five-number总结:
- 最小值
- Q1:第25百分位
- Q2:中位数
- Q3: 75%
- 最高值(第四季)
这些五位数的摘要可以很容易地使用盒状和须状图进行可视化。
标准偏差
的标准偏差是数据集中可变性的平均值。
它告诉你,平均而言,每个分数离平均值有多远。标准差越大,数据集的变量就越大。
手工求标准差有六个步骤:
- 列出每个分数求均值.
- 减去每个分数的平均值,得到与平均值的偏差。
- 对每个偏差进行平方。
- 把所有的方差平方加起来。
- 将方差的平方和除以n- 1 (for a样本)或N(对于人口)。
- 求出你得到的数字的平方根。
| 步骤1:数据(分钟) | 第二步:偏离均值 | 步骤3 + 4:平方偏差 |
|---|---|---|
| 72 | 72 - 207.5 = -135.5 | 18360.25 |
| 110 | 110 - 207.5 = -97.5 | 9506.25 |
| 134 | 134 - 207.5 = -73.5 | 5402.25 |
| 190 | 190 - 207.5 = -17.5 | 306.25 |
| 238 | 238 - 207.5 = 30.5 | 930.25 |
| 287 | 287 - 207.5 = 79.5 | 6320.25 |
| 305 | 305 - 207.5 = 97.5 | 9506.25 |
| 324 | 324 - 207.5 = 116.5 | 13572.25 |
| 意思是=207.5 | Sum = 0 | 平方和=63904 |
n- 1 =7
63904 / 7 =9129.14
年代=√9129.14 = 95.54
你的数据的标准差是95.54.这意味着,平均而言,每个分数偏离平均值95.54分。
总体标准差公式
如果你有来自整个总体的数据,使用总体标准差公式:
| 公式 | 解释 |
|---|---|

|
|
 总体标准差
总体标准差 总和…
总和… =每个值
=每个值 总体平均数
总体平均数 =总体中值的数量
=总体中值的数量样本标准差公式
如果你有来自样本的数据,使用样本标准差公式:
| 公式 | 解释 |
|---|---|

|
|
 样本标准差
样本标准差 样本平均数
样本平均数 =样本中值的个数
=样本中值的个数为什么要使用n- 1为样本标准差?
当你有总体数据时,你可以得到总体标准差的确切值。因为你收集数据从每一个总体成员,标准差反映了你的分布,总体的变异性的精确数量。
但当你使用样本数据时,你的样本标准差总是被用作总体标准差的估计。使用n在这个公式中,往往会给你一个有偏见的估计,始终低估了可变性。
减少样本n来n- 1使标准偏差人为地变大,给你一个变异性的保守估计。
虽然这不是一个无偏的估计,但它是一个偏差较小的估计:高估而不是低估样本的可变性更好。
当样本容量较大时,标准差的偏倚估计和保守估计之间的差异会小得多。
方差
的方差是均值的方差的平均值。偏离平均值是指分数离平均值的距离。
方差是标准差的平方。这意味着方差的单位要比数据集的典型值大得多。
虽然很难直观地解释方差数,但在统计测试中比较不同数据集的方差是很重要的方差分析.
方差反映了数据集中的分布程度。数据越分散,相对于平均值的方差就越大。
年代= 95.5
年代2= 95.5 x 95.5 = 9129.14
数据的方差是9129.14.
要手动找到方差,请执行除最后一步之外的所有标准偏差步骤。
总体方差公式
| 公式 | 解释 |
|---|---|

|
|
 =总体方差
=总体方差 =每个值
=每个值 =总体中值的数量
=总体中值的数量样本方差公式
| 公式 | 解释 |
|---|---|

|
|
 =样本方差
=样本方差有偏方差估计和无偏方差估计
统计中的无偏估计是指不一致地给你高值或低值的估计——它没有系统偏差。
就像标准差一样,总体和样本方差也有不同的公式。但是,虽然标准偏差没有无偏估计,但样本方差有一个。
如果样本方差公式使用样本n,样本方差将偏向于低于预期的数字。减少样本n来n- 1使方差人为增大。
在这种情况下,偏见不仅降低了,而且完全消除了。样本方差公式给出了完全无偏的方差估计。
样本标准差为什么不是无偏估计呢?
这是因为样本标准差来自于样本方差的平方根。由于平方根不是一个线性操作,不像加法或减法,样本方差公式的无偏性不包含在样本标准差公式中。
衡量可变性的最佳方法是什么?
衡量可变性的最佳方法取决于你的测量水平和分布。
测量水平
对于在an处测量的数据序数水平上,极差和四分位间极差是变异的唯一适当度量。
分布
对于正态分布,所有的度量都可以使用。标准差和方差是首选,因为它们考虑了整个数据集,但这也意味着它们很容易受到异常值的影响。
对于有异常值的倾斜分布或数据集,四分位范围是最好的测量方法。它受极值的影响最小,因为它关注的是数据集中间的分布。
关于可变性的常见问题
引用这篇Scribbr文章
如果你想引用这个来源,你可以复制和粘贴引用或点击“引用这篇Scribbr文章”按钮,自动添加到我们的免费引用生成器引用。
班达里,P.(2022年11月11日)。计算范围,IQR,方差,标准偏差。Scribbr。检索于2022年12月14日,来自//www.dandarfirm.com/statistics/variability/
