理解置信区间|简单的例子和公式
当你在统计学上进行估计时,它是否是一个汇总统计数据或者一个检验统计量在美国,这个估计总是有不确定性的,因为这个数字是基于一个样本你正在研究的人群。
的置信区间如果您再次运行实验或以相同的方式重新对总体进行抽样,则您期望您的估计值在一定百分比的时间内下降的值范围。
的置信水平您期望在置信区间的上界和下界之间重现估计值的次数百分比,由alpha值.
置信区间到底是什么?
置信区间是的意思是你的估计加上和减去估计的变化。这是你在重做测试时期望的估计值范围,在一定的置信度范围内。
信心在统计学中,是描述概率的另一种方式。例如,如果您构建了一个具有95%置信水平的置信区间,那么您确信100次估计值中的95次将落在置信区间指定的上下限之间。
置信水平= 1−一个
如果你用的值是p< 0.05为统计显著性,则您的置信水平为1−0.05 = 0.95,即95%。
什么时候使用置信区间?
您可以为许多种统计估计计算置信区间,包括:
- 比例
- 人口意味着
- 总体平均数或比例之间的差异
- 组间变异的估计
这些都是点估计值,并没有给出任何关于数值变化的信息。置信区间对于传递点估计周围的变化是有用的。
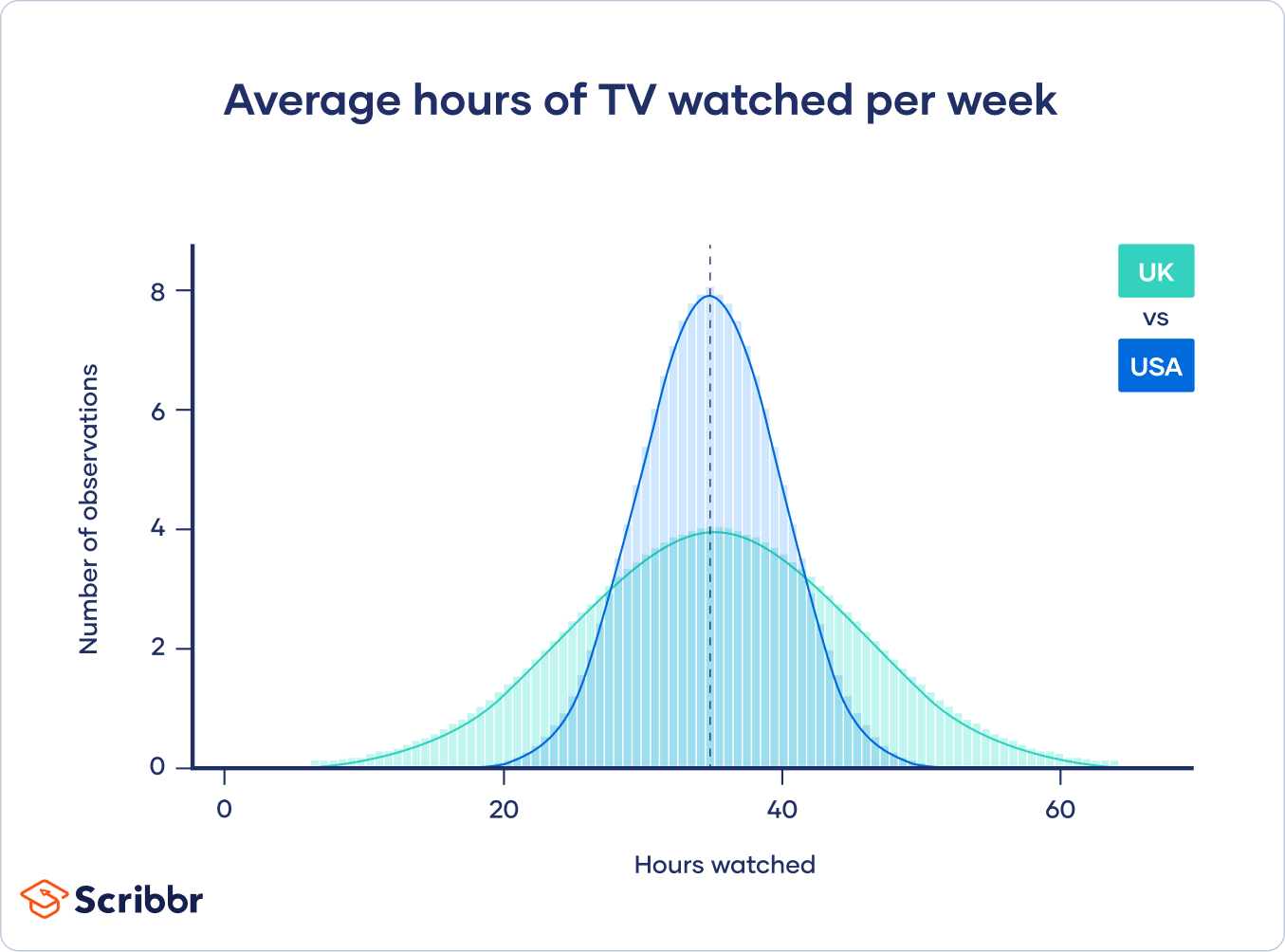
然而,英国人调查在观看时间上有很大的差异,而美国人的观看时间都差不多。
尽管两组人有相同的点估计(观看的平均小时数),但英国人的估计比美国人的估计有更宽的置信区间,因为数据中有更多的变化。
计算置信区间:你需要知道的
当您运行统计测试时,大多数统计程序将包括估计的置信区间。
如果你想自己计算置信区间,你需要知道:
- 也就是你要建立置信区间的点估计
- 测试统计量的临界值
- 的标准偏差样本的
- 样本量
一旦您知道了这些成分中的每一个,您就可以通过将它们代入与数据对应的置信区间公式来计算估计值的置信区间。
点估计
您的置信区间的点估计将是您所做的任何统计估计(例如,总体均值,总体均值之差,比例,组间变异)。
求临界值
临界值告诉你有多少标准差为了达到置信区间的期望置信水平你需要远离均值。
求临界值有三个步骤。
- 选择你的alpha (α)值。
值是统计显著性的概率阈值.最常见的alpha值是p= 0.05,但有时也使用0.1,0.01,甚至0.001。最好看看研究论文在您的领域中发布,以决定使用哪个alpha值。
- 决定你需要的是单尾区间还是双尾区间。
你很可能会使用双尾间隔,除非你在做单侧t测验.
对于双尾区间,将alpha除以2得到上下尾的alpha值。
- 找出与alpha值相对应的临界值。
如果您的数据遵循a正态分布,或者如果你的样本量较大(n> 30)近似正态分布,你可以使用z分布找到临界值。
对于一个z统计方面,一些最常见的值如下表所示:
| 置信水平 | 90% | 95% | 99% |
|---|---|---|---|
| 对于单尾CI | 0.1 | 0.05 | 0.01 |
| 双尾CI的 | 0.05 | 0.025 | 0.005 |
| z统计 | 1.64 | 1.96 | 2.57 |
如果您使用的是近似正态分布的小型数据集(n≤30),请使用t分布代替。
的t分布遵循相同的形状z分布,但校正小样本容量。为t分销,你需要知道你的自由度(样本量- 1)。
看看这套t表去寻找你的t统计。我们已经把置信度和p值用于单侧和双侧测试,以帮助您找到t你需要的价值。
对于正态分布,比如t分布和z分布中,均值两侧的临界值相同。
对于双尾95%置信区间,alpha值为0.025,对应的临界值为1.96。
这意味着,为了计算置信区间的上界和下界,我们可以从平均值取平均值±1.96个标准差。
求标准差
大多数统计软件都有一个内置的函数来计算你的标准偏差,但要手动找到它,你可以先找到你的样本方差,然后取平方根得到标准偏差。
- 求样本方差
样本方差定义为与均值差的平方和,也称为均方误差(MSE):

要找到MSE,请从数据集中的每个值中减去样本平均值,平方得到的数字,然后除以该数字n−1(样本量- 1)。
然后将所有这些数字相加,得到总样本方差(年代2).对于较大的样本集,在Excel中最容易做到这一点。
- 求标准差。
的标准偏差你的估计(年代)等于样本方差/样本误差的平方根(年代2):

- 10 GB估计。
- 美国估计为5。
样本大小
样本量是数据集中观测数据的数量。
正态分布数据均值的置信区间
正态分布数据在图上绘制时形成钟形,样本均值在中间,其余数据相当均匀地分布在均值的两侧。
符合标准正态分布的数据的置信区间为:

地点:
- CI =置信区间
- X̄总体平均数
- Z* =的临界值z分布
- σ =总体标准差
- √n =总体规模的平方根
的置信区间t分布遵循相同的公式,但替换了Z*与t*.
在现实生活中,你永远不会知道人口的真实值(除非你能做一次完整的人口普查)。相反,我们用样本数据中的值替换总体值,因此公式变成:

地点:
- x =样本均值
- S =样本标准差
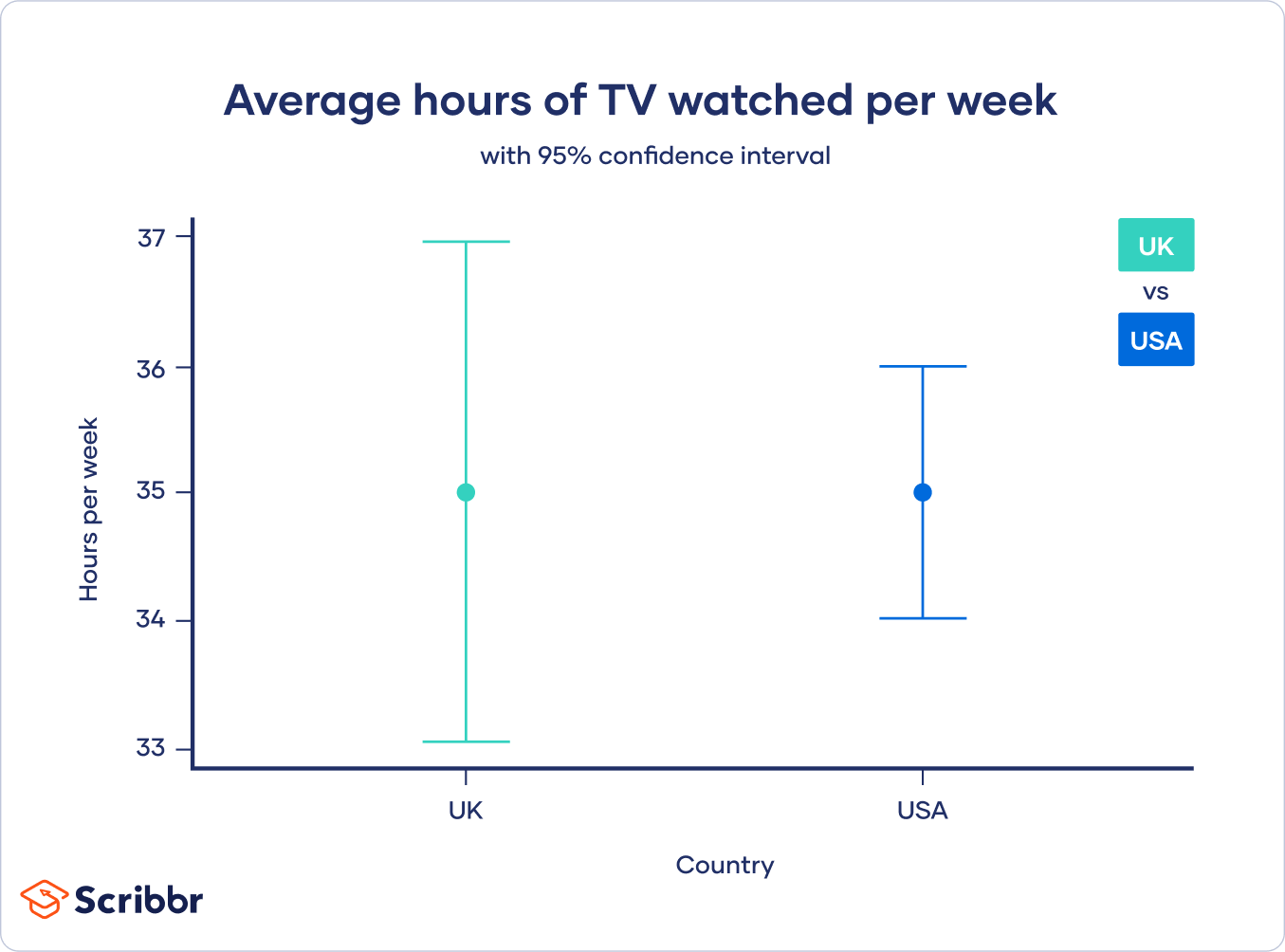
要计算95%置信区间,我们可以简单地将这些值代入公式。
美国方面:

因此,对于美国来说,95%置信区间的下限和上限分别为34.02和35.98。
GB:

因此对于GB, 95%置信区间的下界和上界分别为33.04和36.96。
比例置信区间
比例的置信区间与均值的置信区间遵循相同的模式,但在标准差的地方,您使用样本比例乘以1减去比例:

地点:
- p =在你的样本中所占的比例(例如,表示自己看过电视的受访者的比例)
- Z*=的临界值z分布
- N =样本量
非正态分布数据的置信区间
要计算非正态分布数据平均值附近的置信区间,您有两个选择:
- 您可以找到与数据形状匹配的分布,并使用该分布来计算置信区间。
- 您可以对数据执行转换,使其符合正态分布,然后为转换后的数据找到置信区间。
执行数据转换在统计学中非常常见,例如,当数据遵循对数曲线时,但我们希望将其与线性数据一起使用。当你计算置信区间的上界和下界时你只需要记住对你的数据做反向变换。
报告置信区间
论文中有时会报告置信区间,但研究人员更经常报告他们估计的标准差。
如果要求报告置信区间,则应包括置信区间的上界和下界。
在图表中经常使用置信区间。当显示组间差异或绘制线性回归时,研究人员通常会包括置信区间,以给出估计值周围变化的可视化表示。
使用置信区间时要谨慎
置信区间有时被解释为你估计的“真实值”在置信区间的范围内。
事实并非如此。置信区间不能告诉你你找到统计估计值的真实值的可能性有多大,因为它是基于样本,而不是整体人口.
置信区间只告诉你,如果你重新进行抽样或以完全相同的方式再次进行实验,你可以期望找到的值的范围。
你的抽样计划越准确,或者你的实验越真实,你的置信区间包含估计值的真实值的可能性就越大。但这种准确性是由你的研究方法决定的,而不是由你收集数据后所做的统计决定的!
关于置信区间的常见问题
- 置信区间和置信水平之间的区别是什么?
-
的置信水平是如果您再次运行实验或以相同方式重新对总体进行采样,您期望接近相同估计值的次数百分比。
的置信区间由您期望在给定置信水平下找到的估计的上界和下界组成。
例如,如果你根据婴儿随机样本估计每年出生的女婴平均比例的95%置信区间,你可能会发现上界为0.56,下界为0.48。这些是置信区间的上界和下界。置信水平为95%。
引用这篇Scribbr文章
如果你想引用这个来源,你可以复制和粘贴引用或点击“引用这篇Scribbr文章”按钮,自动添加到我们的免费引用生成器引用。
贝文斯,R.(2022年11月18日)。理解置信区间|简单的例子和公式。Scribbr。检索于2022年12月19日,来自//www.dandarfirm.com/statistics/confidence-interval/
